
I went to Google Cloud Next 2026 expecting to come back excited about new models.
I came back excited about plumbing.
Across speakers from Google, AT&T, Shopify, Anthropic, Capgemini, Salesforce, Equifax, AKQA. One idea kept showing up in different costumes. Memory.
Not as a feature. As the thing that decides whether your agent is a neat demo or something a team can actually rely on.
I've been writing about this for a while. Everything is a markdown file now was my version of it. Context is king was the longer version. What surprised me at GCN was how openly the rest of the industry is now saying the same thing on the main stage.
This post is my full notes from my favorite 8 sessions. It's long. It's organized by session, in the order I attended them. The memory thread is loud, but there's also stuff on long-running agents, sub-agent design, generative UI, governance, and migration patterns.
Watch how often memory comes back up.
1. Agent Context Engineering
Speakers: George Lee (PM, Google Cloud), Kimberly Milam (SWE, Google Cloud), Jeff Dixon (Head of Digital Product, AT&T) and Preethi Prabhakar (Principal Engineer, AT&T).
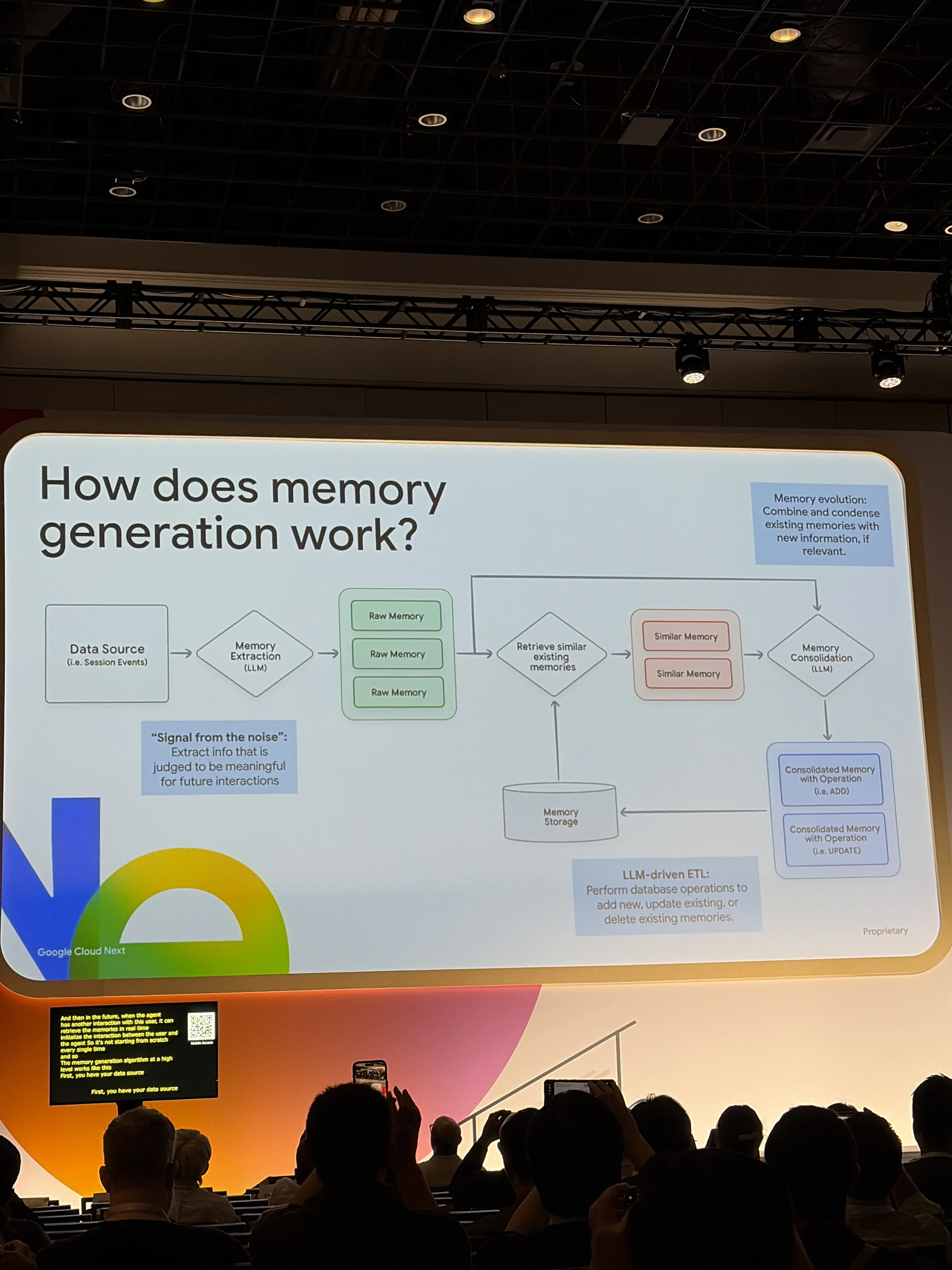
This was the most explicit memory session of the conference. Four speakers, one topic: how do you keep an agent useful past the first prompt.
The opener set the frame: LLMs are inherently stateless. Every conversation starts from zero. The illusion of bigger context windows hides a real problem called context rot. The bigger the window, the worse the model gets at finding what matters inside it.
Three pitfalls of context engineering:
- Too little context: the agent guesses
- Too much context: the agent drowns in it
- Wrong context: the agent confidently does the wrong thing
The Goldilocks zone is narrow. And the math is brutal: if every step of an agentic loop is 95% accurate, three steps in you're already at 85.7%. Five steps in, you're below 77%.
The Google ADK team announced two things:
- Memory Bank: managed long-term memory for ADK agents. Sessions for short-term, Memory Bank for long-term. A real ETL pipeline: extract from conversations, consolidate into facts, store with retrieval ready.
- Memory Profiles (new). Control what gets remembered and what gets ignored. Not everything in a conversation is worth keeping.
Then AT&T came on stage and made it concrete with the barista metaphor. Imagine your local coffee shop, but every morning the barista has full amnesia. You'd give up after a week. That's what most agents are right now.
AT&T runs hundreds of products, millions of customers, agents that work alongside human reps. They built a multi-agent system where memory is the connective tissue. Tenure for an AI agent is measured in conversations, not months. Without persistent memory, every conversation is day one.
The whole session was a wake-up call: you don't fix bad agent behavior by adding more context. You fix it by getting the right context at the right time.
2. Long-Running AI Agents
Speakers: Addy Osmani (Director Cloud AI, Google Cloud)
The framing here was clean. Chatbots are single-turn. They reset every session. Long-running agents operate for hours or days, configure their own goals, run agentic loops with self-correction, and resume after interruptions.
That's the next step. And every team trying to get there hits the same three walls:
- Context degradation over time: even million-token windows lose coherence
- No persistent state: the agent drifts, breaks, gives up
- No self-verification: it can't tell if it's actually done
The session walked through three breakthroughs:
- The Agent Harness: Plan, Build, Evaluate. Three specialized agents, not one monolith. Git commits at every step, automated tests, workspace ready for the next shift.
- Persistent memory as markdown files: living plans as markdown, changelogs as lab notes, test oracles for self-verification.
- The "Ralph loop": kick the agent back when it claims it's done prematurely. Add a verification step that can call BS.

The use cases that landed for me: a 24/7 competitor monitor that runs on its own schedule and surfaces what changed, and a 3D asset pipeline where the agent picks up overnight where the human left off.
Cloud-side, Google announced Agent Engine (GA) with Sessions for short-term state and Memory Bank for long-term memory. Managed infrastructure version of the harness patterns.
If you've been following my one year of building AI agents post, this is the same playbook I've been advocating for, but now packaged as a cloud product. The hard part is no longer the architecture. It's the discipline.
3. Real-Time AI Agents
Speaker: Annie Wang / Qingyue Wang (AI/ML Advocate, Google).
Topic: building personalized multimodal voice agents with Google ADK. Real-time voice plus persistent memory plus low-latency recall.
The arc was three parts.
Part 1: Real-time voice. Half-duplex (push to talk, wait for reply) versus full-duplex (you can interrupt the agent mid-sentence, it can interrupt you). The Live API is audio-native. No speech-to-text round trip. The agent hears you directly.
Part 2: ADK Runner. The secret weapon. Execution Logic plus LiveRequestQueue. This is what turns a model call into a real-time conversation loop.
Part 3: Memory. Three layers:
- Working memory: the current turn
- Structured memory: Cloud SQL, things like user preferences and history
- Unstructured memory: Vertex AI Memory Bank, distilled facts from past conversations

The demo was the moment. Annie's agent knew what she wanted before she finished the sentence. Background consolidation in the previous session had stored the relevant fact. Low-latency recall pulled it the moment the conversation pattern matched.
She walked through three tricks for low latency: pre-warming the cache, parallelizing retrieval, and structuring the prompt so the model doesn't have to scan the whole memory store.
If you've ever been frustrated by a voice assistant asking "what was your name again?", this is the answer to it.
4. Shopify Sidekick
Speakers: Andrew McNamara (Director of Applied ML, Shopify), Rodrig Olivares (Applied AI Engineering, Anthropic)
This was my favorite session of the whole conference.
Sidekick is the AI co-founder Shopify built for millions of merchants in 175+ countries. It works because of a small set of architectural principles that the team has held the line on while everyone else has been chasing complexity.
The principles that hit hardest:
Simple wins. Single orchestration loop, not multi-agent. Shopify resisted the temptation to build a sprawling multi-agent system. One main loop. Tools. Sub-agents only when they earn their place.
I'm fully aligned with this. Most people building with AI right now think more sub-agents equals smarter system. It's the opposite. Every sub-agent you add is another thing that can drift, hallucinate, or just confuse the orchestrator. The right number of sub-agents is the smallest number that solves the problem. Usually that's zero. Sometimes one. Almost never four.
I wrote about this dynamic in skills vs agents in Claude Code. The jar metaphor explains why every sub-agent has a real cost.
Build for the model that's coming, not the one you have. Rodrigo's line. Don't optimize so hard against today's model that you can't move when the next one ships. Sidekick swapped from Claude 4.5 to 4.6 in 24 hours because their architecture didn't have model-specific hacks baked in.
Tool design at the lowest level. 16 tools beats 100. Tool sprawl is the silent killer. The fewer, better-designed tools an agent has, the more reliably it picks the right one.
Sub-agents must earn their place. A sub-agent is a tool that runs its own loop. That's it. So treat it like a tool. If you can solve the problem without it, don't add it.
Return data, not language. When a sub-agent reports back to the outer model, it returns structured data, not prose. Prose biases the outer model's reasoning. Data lets it think clearly.

On evals: Sidekick runs a self-healing flywheel. User simulator generates conversations. LLM judge scores them. Failures feed back into the eval set automatically. That's how they swapped models in a day.
The last quote of the session was the one I wrote down twice: "Discipline. So much of building good agents comes down to discipline." That's the whole thing. The tools are easy. The discipline of saying no to complexity is the hard part.
5. Apigee + MCP
Speakers: Senthil Doraiswamy (PM, Google Cloud), Adrian Tatsch (VP of AI Technology & Innovation, Equifax), David Rush (CE, Google Cloud).
This is the enterprise governance angle. I covered the high-level take on Google's enterprise focus in my first GCN recap on LinkedIn, but the implementation matters and this session went deep on it.
Three-step framework for moving from API sprawl to agentic-ready:
- Enhance existing APIs with the metadata agents need
- Translate them into MCP tools automatically
- Govern them centrally

Native AI Gateway controls in Apigee handle the governance layer. Tool-level governance via JSON-RPC means you can decide which agents can call which tools, with which arguments, under which conditions. That sounds boring until you imagine an agent with access to your billing API and no guardrails.
The real moment was Equifax. 125 years old, $6 billion revenue, calling themselves agentic-ready. Adrian's two best lines:
- "Are we talking about technology or a disgruntled four-year-old?". On agent governance
- "We don't need to sit back and wait for everything to mature. We can co-create together and define what the future is of agents."
Equifax made a cloud bet in 2018 that everyone called too early. They're now reaping it. The lesson is the same as the Shopify session: build for the model that's coming.
6. Conversational Analytics
Speakers: Richard Kuzma (PM, Google Cloud), Marc Wollnik (Senior Customer Solutions Engineer, Google Cloud), Sudhir Reddy (EVP & Group CIO, Capgemini), Arul Krishnan (Director of Data Analytics, Capgemini).
The framing slide was a timeline: data work used to take months, then weeks, then days. Now seconds. And it's heading toward autonomous.
The product side: Conversational Analytics is being embedded everywhere, Looker, BigQuery, Workspace, Slack, custom apps via ADK + MCP. Three paths to data insights, all converging on natural language.
Capgemini built an Enterprise Intelligence Platform they call Neon. The architecture they shared was instructive. The hard part isn't the LLM. It's the line between deterministic and probabilistic.
For numbers and aggregations, you want deterministic. SQL, aggregations, deterministic results. For interpretation and recommendations, you want probabilistic. The agent's judgment.
Most failed analytics agents collapse this distinction and let the LLM do math. It hallucinates. Capgemini split it: SQL is generated and verified, then the LLM reasons over the verified result.
Trust pillars in their architecture:
- Observability
- FinOps (cost per query, cost per agent)
- Evals
- Memory (callback to the thesis. They said it explicitly)
Google also announced agentic workflows with explicit autonomy levels. Early access program is open.
7. Gemini Playbook
Speakers: Daniel Kyme (PM, Google Cloud), Darvish Shadravan (Senior Director of Product, Salesforce), Skander Hannachi (Applied AI Engineering, Google Cloud).
Two halves: optimizing for today, optimizing for tomorrow.
The Optimization Triangle. Pick two of three: cost, latency, quality. You can't have all three. The Gemini portfolio is built around this trade-off: Pro for quality, Flash for balance, Flash-Lite for cost, Gemma 4 for on-device.

Eng2Eng. Google engineers paired with customer engineers. The implicit message: out of the box is just a starting line. Real performance comes from optimization.
The Salesforce Agentforce section was the most impressive single demo of the conference. Bring-your-own-Gemini, model choice per agent, Gemini 3 Flash as the new default. They showed an optimization curve: 0.36 to 0.82 on their internal benchmark, just from prompt tuning and optimization passes.
Four optimization dimensions Salesforce tracks per model: accuracy, latency, cost, safety. System prompts tuned per model, not shared. The lesson: portability sounds nice in theory but in practice you optimize per model.
Skander's migration talk was the part I keep thinking about. Migrating between LLM versions shouldn't feel like a cloud migration. The reason it does is because most teams treat agents like prompts. They're not.
He cited a 2014 paper on ML and technical debt. The line that stuck: "LLMs aren't a credit card. They're a loan shark." The interest compounds fast. Migrating agents is migrating tools, eval suites, memory schemas, and behavioral assumptions, not just text.
Anti-patterns he called out:
- Unintentional hill climbing: tuning by gut feel until you've climbed a local maximum and can't get off
- Tool ambiguity: too many overlapping tools confuses the agent into picking the wrong one (echoes the Shopify "16 tools beats 100" point)
- Spaghetti optimization: random tweaks instead of an intentional process
The fix is process. Blurred MLOps and SDLC pipeline. Architecting for resilience.
8. Generative UI for Any Agent
Speakers: Alan Blount (PM, Google Cloud), Ido Salomon (Co-Creator, MCP Apps), Atai Barkai (CEO, CopilotKit & AG UI), Nicolas Le Pallec (CTO, AKQA).
This was the session almost no one is talking about on LinkedIn yet, and I think it's the most important one for the next 18 months.
The thesis: text isn't enough. We've been treating agents like chat. The next phase is agents that generate UI on the fly, in your existing app surfaces.
There's a protocol war happening that almost nobody outside this room knows about: A2UI (Google), AG-UI (CopilotKit), MCP-UI / MCP Apps (Ido Salomon), WebMCP. They're trying to standardize how agents render UI without each app reinventing the wheel.
The UI spectrum to know:
- Predefined: the agent picks from existing UI components
- Declarative: the agent describes UI in a structured language, the app renders it
- Generative: the agent generates UI from scratch on the fly

A2UI is Google's open standard for agent-generated UI. v0.9 today. Architecturally clean: no remote executables, no security holes, renderers handle the actual rendering. Agents describe intent, the user's surface decides how to draw it.
AG-UI from CopilotKit reframes the problem. Agents break the request/response model that web UIs were built for. AG-UI is the third leg of the triangle alongside REST and WebSocket: a protocol designed for streaming, interrupting, multi-turn agentic UI.
The Synthesis demo from AKQA (Nico) was the showstopper. Their pitch is the Intent Economy: users don't want apps, they want outcomes. Decoding intent across functional, emotional, and social dimensions, then generating the interface that fits.
Their before-and-after: a content workflow that took 6 hours of UI clicking, reduced to 10 seconds of intent-driven UI generation. Whether you buy the framing or not, the demo worked.
Why this connects to the memory thesis: generative UI without memory is incoherent. The agent has to remember what you've already seen, what you've already chosen, what you've already rejected, or it generates a new janky interface every turn. Memory is the substrate. Generative UI is the surface.
What I'm taking back
Eight sessions. One signal.
Memory is the difference between a conversation toy and a tool a team can rely on. Every credible enterprise example at GCN (AT&T, Shopify, Capgemini, Salesforce, Equifax) built memory in deliberately. None of them treated it as something to add later.
The other patterns matter too:
- Discipline beats complexity. Smaller tool sets and fewer sub-agents almost always win.
- Process matters more than choice of model. Migrating models without an eval flywheel is a coin flip.
- The next interface battleground is generative UI, and it requires memory to work.
If you're a marketing team trying to figure out where to start with AI agents, my honest advice is: don't pick the model first. Get your context layer right. Get your memory strategy right. The model you pick will be obsolete in six months. The system around it won't.
This is exactly the work I do for clients. If your team is building AI workflows and you want them to outlast the next model release, I help marketing teams build memory and structure into their AI systems.
If you want to keep going on this thread, your folder structure is wasting Claude's brain is the most practical follow-up.
Thanks for reading all the way down. :D

About Alfred Simon
AI Systems Builder & Coach
I build custom AI systems for companies: support email, order processing, content, reporting. I write about context management, AI workflows, and the messy reality of building things with AI. No theory. No hype. Just what survived 30+ agents and a very healthy trash pile :D
Want to build something like this for your team? Let's talk.